AI Engineering
Workflow Automation
Airtable Engineering
UX Design
NBCUniversal | United States
SkyShowtime | Europe (20+ Nations)
AI Engineer, End to End
AI Engineering · LangChain · LLMs · OCR · RAG · Prompt Engineering · Automation Engineering · n8n · Python Scripting · Database Design · Airtable · UX Research · UI/UX Design
One of the most time-consuming daily tasks for the SkyShowtime Imagery Team is resolving tickets submitted by various stakeholders for imagery-related requests. The process is inefficient, difficult, and tedious - small tasks often take unreasonably long due to system load times, tickets require navigating multiple touch points with deep operational knowledge, and many requests involve repetitive or minor updates to legacy titles. On average, operators spend about 25% of their day resolving tickets - the equivalent of $49,000 in annual labor costs across roughly 700 tickets per year.
Build an AI-powered ticketing system that automates requests through LLMs, OCR, and workflow tools like Airtable and n8n - all under human-on-the-loop oversight.
AI-Powered Ticketing Interface
Airtable Database
N8N Orchestration
Delivered over $2.5 million in projected cost avoidance by independently building a system that the internal engineering team scoped would be a three year build.
$96, 000 operational cost savings/ year.
By automatically completing 75% of tickets, this significantly reduces operational time spent to <30min/day.
Because tickets are now automatically completed upon request, queue times for operator availability no longer exist.
Eliminated 95% of cross-team back-and-forth communication related to ticket clarifications, and status checks, reducing blockers and wait times.
Translating Pain Points into AI Automation Solutions.
Small tasks often require unreasonably long process times due to system load time
Completing a ticket usually involves using 4 or more touch points while requiring considerable knowledge.
Many tickets are for small changes, sometimes even for titles that launched years ago.
SkyNet runs automations, automatically in the background through n8n triggers, eliminating the need for manual operation.
Smart orchestration through RAG, MCP, tool calling, and API integration - all embedded in SkyNet.
Similar tickets are cached to accelerate completion of recurring task types.
Through personal experience, research, and investigation of 700+ yearly imagery tickets, I mapped all requests into four distinct categories.
SkyNet is built on a modular architecture that enables independent debugging, upgrades, and operator overrides at every stage of the workflow. Each subsystem - whether it’s AI Engineering, n8n, or Airtable - and the modules within them operate as discrete, self-contained components, making the entire system highly maintainable, adaptable, and resilient to change.
When users submit a ticket, they select a type - or choose “I’m Unsure” - and then describe what’s needed. The Multi-LLM chatbot cross-checks the chosen type against the description using RAG and tool calling to ensure accuracy. After user confirmation, all information is stored in Airtable and passed to n8n, where the corresponding workflow triggers automatically. Once complete, operators are notified and can review results. Please reference the simplified flow below.
= AI driven step
User Enters Ticket Details

AI Verifies & Classifies Ticket

Make New Package

Change Existing Image Assets

Add Missing Image Assets

Publish Artwork to Platform

Operator Reviews (if needed)
Complete!
This project uses two types of AI models: LLMs and OCRs.
LLMs are used in the customer-facing submission form of SkyNet. Their purpose is to classify ticket descriptions into one of four predefined ticket types.
OCR is used in the backend n8n workflow. Its purpose is to inspect PSD layers, extract text, and classify layers for image manipulation.
Workflow overview
When a user submits a ticket, SkyNet first runs hybrid retrieval (Pinecone + SQLite) and feeds that context into a classifier LLM with structured JSON output that predicts the most appropriate request type. An orchestrator function then evaluates confidence, retrieval quality, and the user’s original choice to decide whether to auto-accept the prediction or start a short clarification chat. If a chat is needed, a second, lighter LLM interprets the user’s replies (yes/no/more context/question) and routes the flow until the request type is confirmed, then everything is logged to Airtable.
Why this design matters
This design auto-classifies tickets when confidence is high, and falls back to a guided conversation when confidence is low, looping with the user until it can safely commit to a request type. It catches errors early with confidence thresholds, retrieval checks, and predetermined response templates, rather than silently misrouting tickets. By always giving the user the final say when the model disagrees or is unsure, it respects user intent while still reducing manual effort. The architecture stays modular, explainable, and debuggable: each LLM is specialized (classification vs. chat intent), the orchestrator glues them together with explicit control logic, and individual models can be swapped or upgraded without rewriting the whole workflow.
Hybrid retrieval is used to maximize contextual accuracy. Using Pinecone for vector-based semantic retrieval (top_k = 2) and SQLite for keyword lookups (top_k = 2), both retrievers execute concurrently to minimize latency. Their results are merged and deduplicated into a unified context window, balancing semantic relevance with keyword precision. This design choice reflects how user queries often include explicit terms while relying on deeper contextual intent.

Overall, I use role-structured prompts with strict behavioural constraints to keep every model's output predictable. Certain models are defined as “strict JSON-only classifier for ticket requests” in the system prompt with explicit JSON schemas and priority rules and examples that the models must follow.
This prompt design turns the LLMs into deterministic classifiers rather than open-ended chatbots, which is critical when their outputs determine downstream workflows and Airtable updates.
I chose to use the gpt-5-nano because it is the fastest and most cost-efficient OpenAI model that still meets all accuracy and reliability requirements for this use case. After A/B testing, I also decided not to implement memory storage to reduce both latency and cost, as the results showed little to no improvement in performance or user experience.
Structured JSON output is used in 3 key ways:
1 - Logic routing - The JSON response controls downstream decision paths and system behavior.
2 - Debugging visibility - Select JSON fields are surfaced in chat and logged in Airtable, making it easy to inspect LLM reasoning and troubleshoot failures.
3 - Airtable updates - The {result} field can be written directly into Airtable and used to trigger the next step in the n8n automation.
If the output format is incorrect, the system falls back to a safe “LLM JSON ERROR” payload that redirects to chat instead of crashing.
I designed explicit debug and observability hooks around every LLM decision, like confidence level, reasoning, and final decision. On the backend, show_llm_trace builds a compact Markdown trace that includes the chat parser’s classification, the master classifier’s result and confidence, and the orchestrator’s chosen flow/action. Each assistant message in st.session_state.chat_history stores both the user-visible text and the associated debug trace, which is rendered as a caption beneath the message in the chat UI.
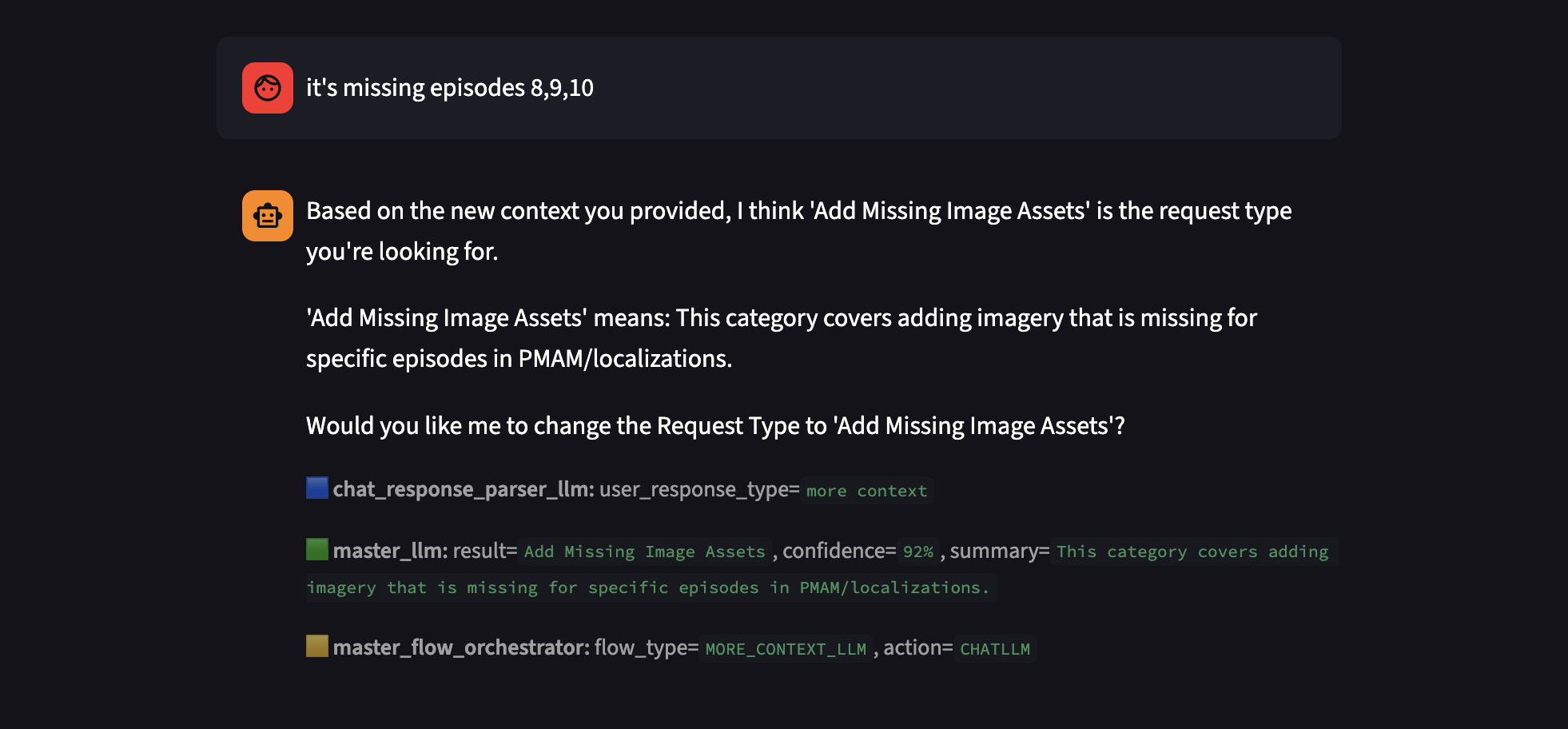
On completion, the entire conversation - including debug traces - is serialized and written back to Airtable’s “Chatbot Chat History” field. This can later be used to refine the system_prompt, update the RAG datasets, or even used for finetuning, if needed.
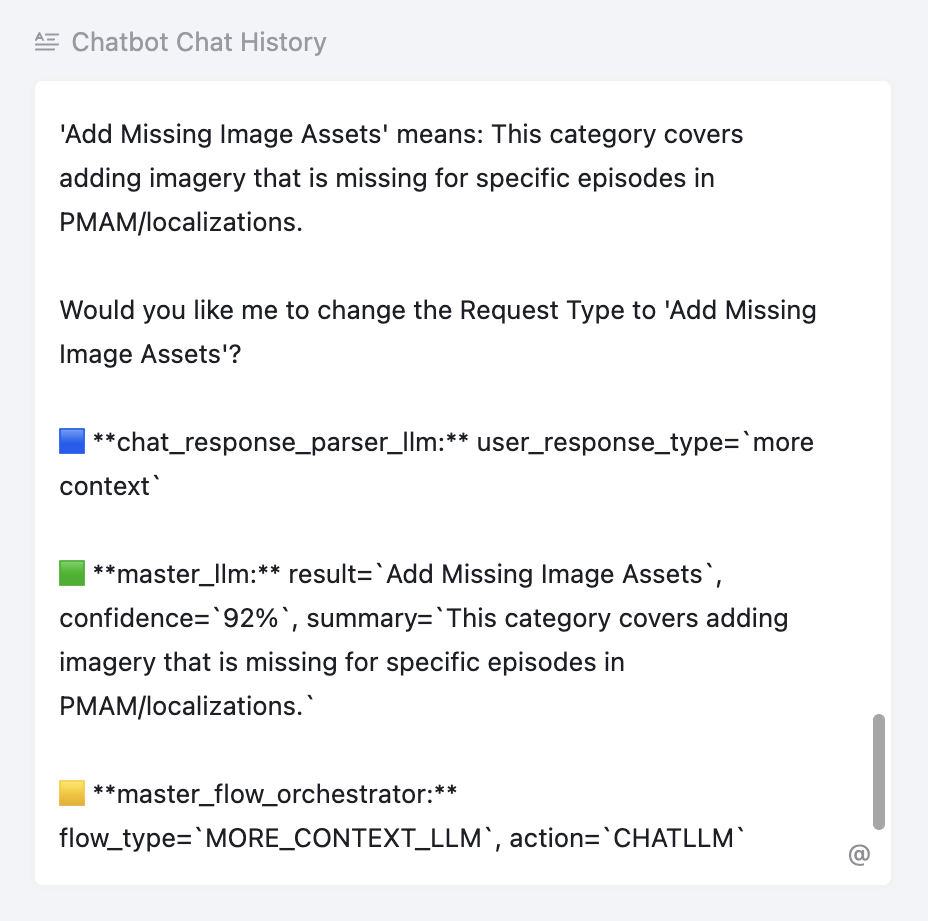
A separate helper also composes a consolidated request description from all user messages into Airtable, which is helpful for future reference. Overall, this design gives operators and engineers a full audit trail of what the model decided, why, and how the flow branched, which is critical for debugging misclassifications and for continuously improving prompts and retrieval quality.
Workflow overview
This system processes Photoshop (PSD) files and classifies each layer as Title Treatment (TT), Artwork, or Unclassified, using a hybrid approach that combines naming heuristics, OCR analysis, and layer-type logic. The pipeline is designed to handle thousands of layers efficiently and safely, while maintaining transparent reasoning for each classification. The flow begins by opening each PSD and extracting layer metadata using inspect_layers(). Each layer is then processed through a multi-stage logic:
1 - Fast Name-Based Classification - Pattern-matching against TT and Artwork heuristics (e.g., "title", "tt", "art") provides instant, no-cost decisions when layer names are meaningful.
2 - OCR-Based Classification - If name heuristics fail, OCR is performed on rendered layer pixels using Tesseract. The system automatically flattens transparency over both black and white backgrounds to maximize text detection confidence. Layer classification depends on detected word count, mean confidence, and pixel coverage.
3 - Inheritance & Structural Rules - Clipping masks inherit their parent classification, invisible and group layers are skipped safely, and fallback cases are labeled "Unclassified" instead of crashing.
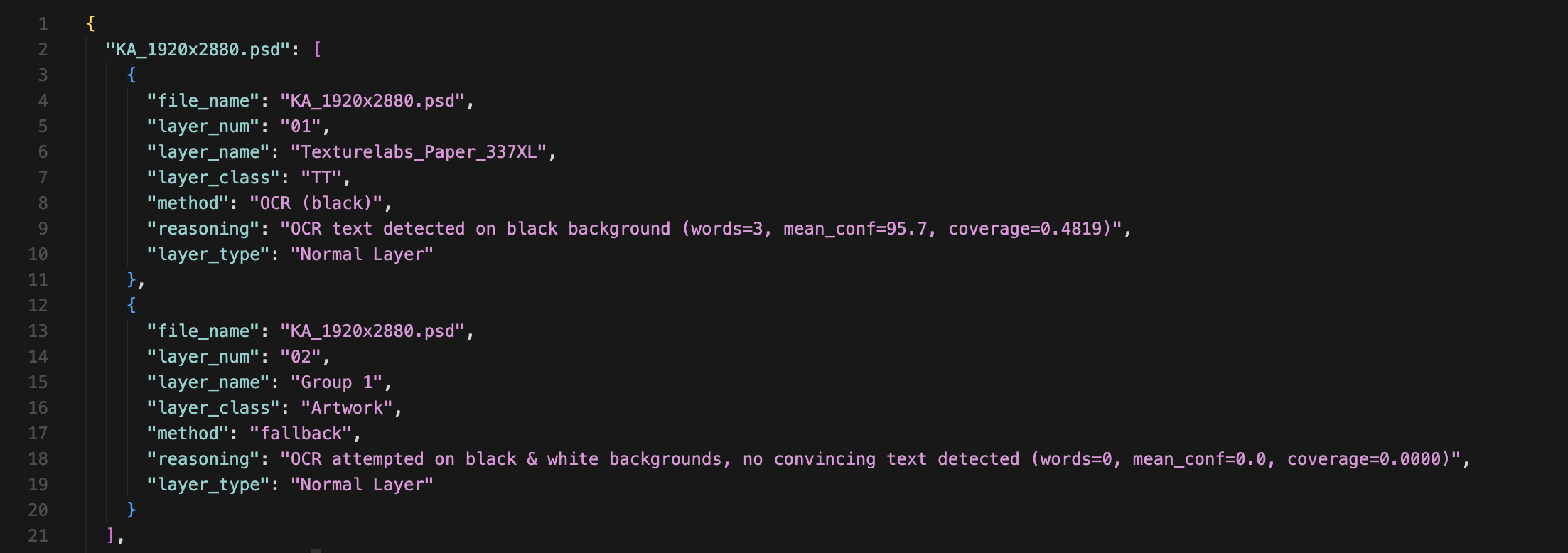
Processing is parallelized via ProcessPoolExecutor, enabling multi-core OCR at scale without blocking. Results are saved as structured JSON and printed layer-by-layer to support visual verification and downstream automation.
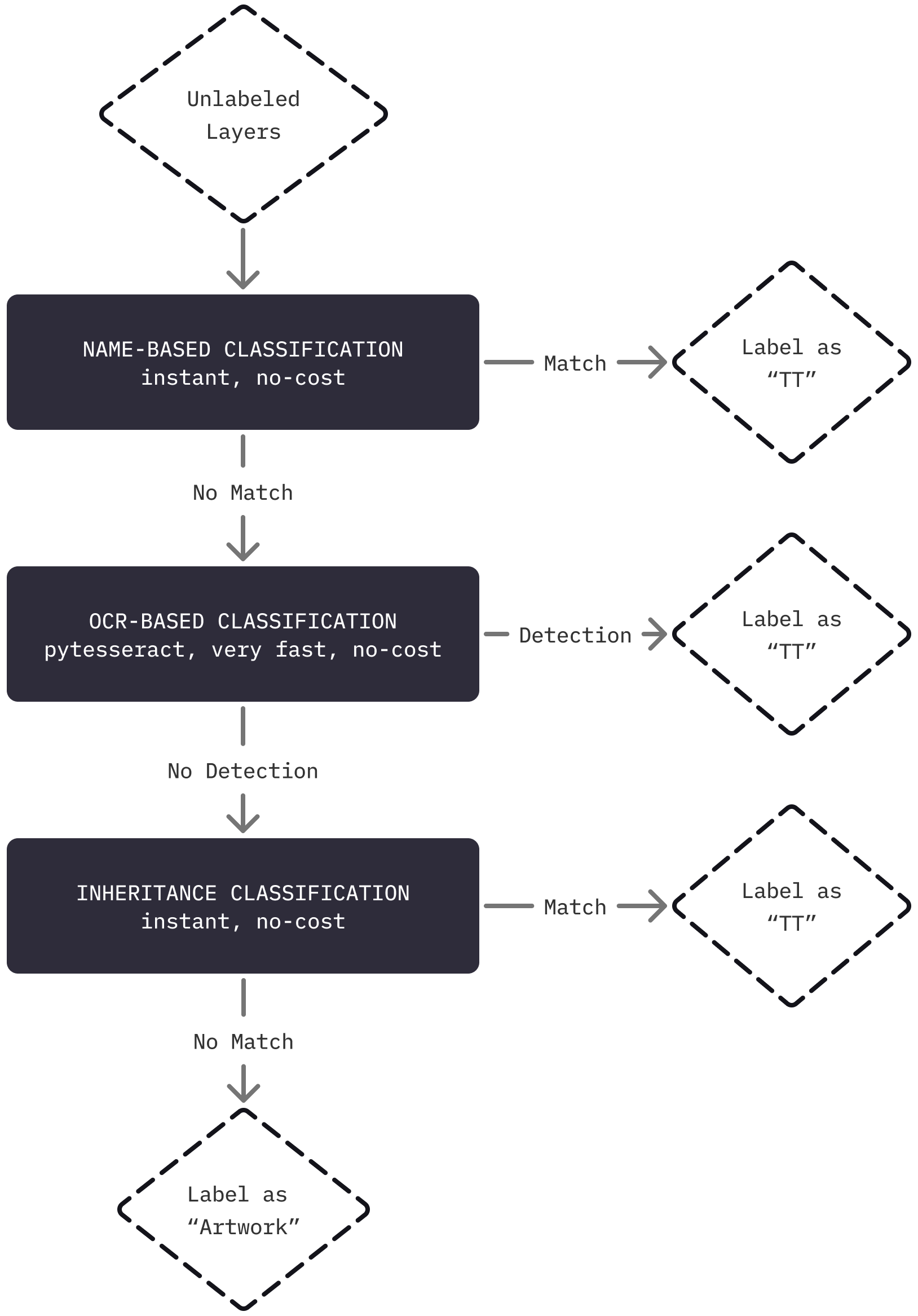
I chose Tesseract via pytesseract because it is lightweight, easily scriptable, and requires no external API dependencies. More importantly, it supports raw pixel inspection, which is critical for accurately distinguishing text layers from artwork. To improve detection quality, the system forces RGBA → RGB conversion, computes words, mean_conf, and coverage metrics, uses configurable thresholds: min_words, min_mean_conf, and min_coverage, and flattens transparency against both black and white backgrounds. This two-pass approach (black, then white) ensures both light and dark title treatments can be detected reliably. It is important to note that switching to an OpenAI Vision model in the future may be a good choice to increase robustness - especially for heavily stylized or skewed text. Today, Tesseract remains the optimal choice given current latency, cost, and dependency constraints.
Debugging is built directly into the pipeline design, with every variable printed on demand. Because this runs in teh backend through n8n automations, it is not visible unless ran directly through terminal or viewed through the saved JSON file, which enables later audits and inspections, reruns directly from that step, and dataset creation. This makes the classifier observable, explainable, and production-safe, even while running parallel OCR at scale.
Debugging is built directly into the pipeline. Every classification decision is printed on demand, including layer number, name, class, method, reasoning, and layer type. Since this system runs in the background via n8n automations, the logs are not visible in real time - but all outputs are saved to JSON for later inspection, enabling:
1 - Full auditability and traceability
2 - Reruns from any point in the process
3 - Dataset creation for future training
4 - Clear failure analysis without guessing
Together, these features make the classifier observable, explainable, and production-safe, especially while running parallel OCR at scale.
After confirming the Ticket Type, a master n8n orchestrator receives a webhook call, and redirects to the corresponding automation. Most automation has to do with internal software, which will not be displayed. However, I will explain the most sophisticated workflow - Making a New Package, which involves OCR through PSD files, file manipulation, Airtable Automation, and shell commands.
the orchestrator. n8n links all the following together.
Sets up the psd files for image manipulation
The setup, 2
The activator
Through personal experience, research, and investigation of 700+ yearly imagery tickets, I mapped all requests into four distinct categories.
SkyNet is built on a modular architecture that enables independent debugging, upgrades, and operator overrides at every stage of the workflow. Each subsystem - whether it’s AI Engineering, n8n, or Airtable - and the modules within them operate as discrete, self-contained components, making the entire system highly maintainable, adaptable, and resilient to change.
When users submit a ticket, they select a type - or choose “I’m Unsure” - and then describe what’s needed. The Multi-LLM chatbot cross-checks the chosen type against the description using RAG and tool calling to ensure accuracy. After user confirmation, all information is stored in Airtable and passed to n8n, where the corresponding workflow triggers automatically. Once complete, operators are notified and can review results. Please reference the simplified flow below.



